Khi thế giới hướng tới một tương lai dựa trên dữ liệu nhiều hơn, nhu cầu về các công cụ thu thập dữ liệu hiệu quả và đáng tin cậy ngày càng trở nên quan trọng.
Trình duyệt cạo dữ liệu Bright là một trong những công cụ đang trở nên phổ biến đối với các chuyên gia và người đam mê dữ liệu.
Trong suốt bài đánh giá này, chúng ta sẽ xem xét các tính năng và lợi ích của Bright Data Scraping Browser và khám phá các ứng dụng tiềm năng của nó trong các tình huống thực tế.
Trình duyệt cạo dữ liệu sáng là gì?
Với Trình duyệt cạo dữ liệu sáng, bạn có thể cạo dữ liệu bằng trình duyệt tự động. Nó là một công cụ cho phép các nhà phát triển và doanh nghiệp trích xuất dữ liệu từ các trang web mà không cần can thiệp thủ công.
Trình duyệt Scraping tự động hóa quá trình trích xuất dữ liệu, giúp việc trích xuất lượng lớn dữ liệu từ các trang web trở nên dễ dàng và hiệu quả hơn.
Bright Data Scraping Browser được phát triển bởi Bright Data, nhà cung cấp hàng đầu các giải pháp thu thập dữ liệu và tích hợp dữ liệu web.
Mục tiêu của công ty là cung cấp cho các doanh nghiệp những công cụ họ cần để thu thập và phân tích dữ liệu web trên quy mô lớn, để họ có thể đưa ra quyết định sáng suốt dựa trên thông tin chính xác và cập nhật.
Trình duyệt Scraping được thiết kế thân thiện và dễ sử dụng, ngay cả đối với những người không có kinh nghiệm với cạo dữ liệu.
Đây là một công cụ mạnh mẽ giúp tiết kiệm thời gian và tài nguyên, khiến nó trở thành một công cụ thiết yếu cho các doanh nghiệp và nhà phát triển dựa vào dữ liệu web để đưa ra quyết định.

Các ứng dụng thực tế của trình duyệt cạo dữ liệu Bright
1. Thương mại điện tử:
Các nhà bán lẻ trực tuyến có thể sử dụng Bright Data Scraping Browser để theo dõi giá, mức tồn kho và khuyến mãi của đối thủ cạnh tranh.
Thông tin này có thể giúp họ đưa ra các quyết định về giá cả và hàng tồn kho sáng suốt, mang lại cho họ lợi thế cạnh tranh trên thị trường.
2. Tiếp thị:
Trình duyệt Scraping có thể được các nhà tiếp thị sử dụng để thu thập dữ liệu về hành vi, sở thích và mối quan tâm của đối tượng mục tiêu của họ.
Thông tin này có thể giúp họ phát triển các chiến dịch tiếp thị được nhắm mục tiêu và hiệu quả hơn, gây được tiếng vang với đối tượng của họ.
3. Tài chính:
Trình duyệt Scraping có thể được các nhà phân tích tài chính sử dụng để thu thập dữ liệu về giá cổ phiếu, xu hướng thị trường và các thông tin tài chính khác.
Thông tin này có thể giúp họ đưa ra quyết định đầu tư tốt hơn và cải thiện hiệu suất danh mục đầu tư tổng thể của họ.
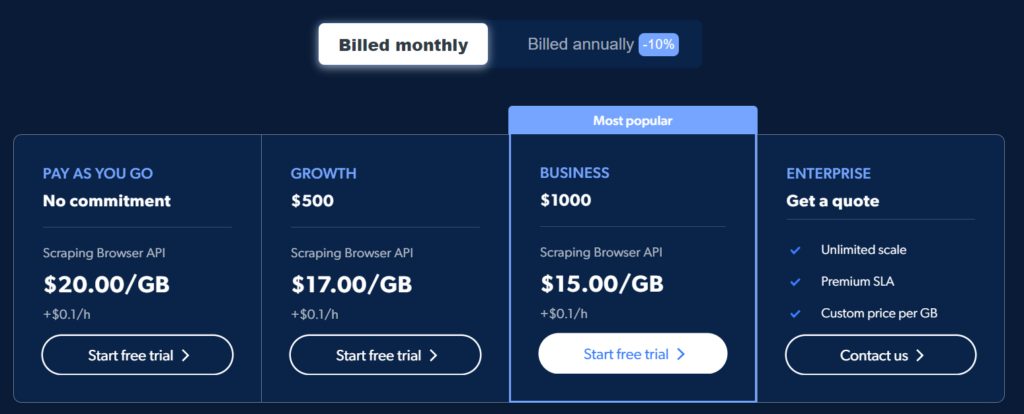
Làm thế nào để Trình duyệt Scraping vượt trội hơn các trình duyệt không đầu?
Bright Data Scraping Browser hoạt động tốt hơn các trình duyệt headless theo nhiều cách. Trình duyệt không đầu là công cụ tự động có thể mô phỏng trình duyệt web không có giao diện người dùng đồ họa, giúp chúng nhẹ và nhanh.
Tuy nhiên, chúng có những hạn chế khi thực hiện các tác vụ thu thập dữ liệu.
Đầu tiên, các trình duyệt không đầu thiếu khả năng xử lý các biện pháp chống cạo mà các trang web thực hiện để chặn các hoạt động cạo.
Mặt khác, Bright Data Scraping Browser có các tính năng tích hợp có thể bỏ qua các biện pháp như CAPTCHA và lấy dấu vân tay, làm cho nó trở thành một công cụ đáng tin cậy hơn để thu thập dữ liệu.
Thứ hai, các trình duyệt không đầu không thể xử lý các dự án cạo quy mô lớn yêu cầu nhiều phiên và thông lượng cao.
Bright Data Scraping Browser, với khả năng xử lý hàng chục nghìn phiên cùng lúc, rất lý tưởng cho các dự án quy mô lớn và có thể cải thiện đáng kể hiệu quả.
Thứ ba, các trình duyệt không đầu có thể không tương thích với một số API cạo phổ biến như Puppeteer.
Tuy nhiên, Bright Data Scraping Browser hoàn toàn tương thích với Puppeteer, được sử dụng rộng rãi cho các tác vụ tự động hóa và cạo.
Khả năng tương thích này cho phép các nhà phát triển có nhiều quyền kiểm soát hơn đối với trình duyệt và các chức năng của nó, giúp nó trở nên hiệu quả và đáng tin cậy hơn.
Câu hỏi thường gặp về Đánh giá trình duyệt cạo dữ liệu sáng
Trình duyệt quét dữ liệu Bright có dễ sử dụng không?
Có, nó rất thân thiện với người dùng và không yêu cầu kinh nghiệm mã hóa. Trình duyệt Scraping đi kèm với một giao diện đơn giản và trực quan giúp mọi người dễ dàng sử dụng.
Làm thế nào Bright Data Scraping Browser có thể giúp tôi tiết kiệm thời gian và tài nguyên?
Trình duyệt Scraping loại bỏ nhu cầu người sáng tạo xây dựng cơ sở hạ tầng của riêng họ hoặc phụ thuộc vào các dịch vụ của bên thứ ba. Cạo dữ liệu dễ dàng với trình duyệt, làm cho nó trở thành một công cụ có giá trị giúp tiết kiệm thời gian và tiền bạc.
Bright Data Scraping Browser có mở rộng được không?
Có, nó hoàn hảo cho các dự án quét dữ liệu quy mô lớn nhắm mục tiêu nhiều trang cùng một lúc. Trình duyệt này cho phép bạn nhận thông tin từ nhiều trang web cùng một lúc vì nó được tạo để xử lý nhiều phiên.
Bright Data Scraping Browser có thể xử lý các khối trang web không?
Có, nó xử lý các khối mới, dấu vân tay, CAPTCHA và thử lại ngay lập tức và có vẻ là người dùng thực. Các lập trình viên không phải chi tiền cho các dịch vụ của bên thứ ba hoặc bỏ chặn các trang web theo cách thủ công khi sử dụng Scraping Browser.
Bright Data Scraping Browser có tương thích với Puppeteer không?
Nó hoạt động với Puppeteer, một API nổi tiếng để thu thập dữ liệu bằng tự động hóa. Do đó, Scraping Browser tránh được ngay cả những tập lệnh và khối khó nhất được thiết kế để phát hiện bot tốt hơn so với các trình duyệt tự động và trống rỗng.
Trình duyệt cạo dữ liệu Bright an toàn như thế nào?
Trình duyệt Scraping đi kèm với nhiều lớp bảo mật, bao gồm xoay vòng IP, giải CAPTCHA và mạng proxy tích hợp. Điều này làm cho nó trở thành một công cụ an toàn cho các dự án thu thập dữ liệu.
Tôi có thể bắt đầu sử dụng Bright Data Scraping Browser như thế nào?
Bạn có thể đăng ký dùng thử miễn phí trên trang web Bright Data và bắt đầu ngay với Trình duyệt Scraping. Trang web cũng cung cấp các hướng dẫn và hỗ trợ khách hàng để giúp bạn bắt đầu.
Liên kết nhanh:
Kết luận: Đánh giá trình duyệt Bright Data Scraping 2024
Trình duyệt cạo dữ liệu Bright là trình duyệt tự động tất cả trong một được thiết kế cho mục đích cạo dữ liệu.
Các tính năng và lợi ích của nó làm cho nó trở thành một công cụ đáng tin cậy cho các dự án thu thập dữ liệu và khả năng tương thích với Puppeteer khiến nó trở nên hiệu quả và đáng tin cậy hơn.
Các ứng dụng thực tế trong các ngành như thương mại điện tử, tiếp thị và tài chính cho thấy phạm vi sử dụng đa dạng của công cụ này.
Khi tầm quan trọng của dữ liệu tiếp tục tăng lên, Bright Data Scraping Browser là một công cụ có thể giúp các chuyên gia dữ liệu và những người đam mê luôn dẫn đầu cuộc chơi.