A Fight That Reveals Who Owns the Internet’s Knowledge Layer

The founder of Wikipedia said something this week that is going to keep coming up in conversations about AI, data, and the economics of the web for the next several years.
The founder of Wikipedia said large language models have been hammering Wikipedia’s servers and AI companies should chip in and pay a fair share for the infrastructure they depend on.
Wikipedia is the most cited source in ChatGPT at 7.8% of all citations — higher than any other single domain. Every time a user asks an AI chatbot about a person, a place, an event, or a concept and the AI cites a factual source, there is a very high probability that Wikipedia is in the answer.
The AI companies have been treating Wikipedia as free, always-available infrastructure. Wikipedia has been absorbing the server costs of supporting that usage while operating as a non-profit funded by donations.
The Broader Data Economy Question
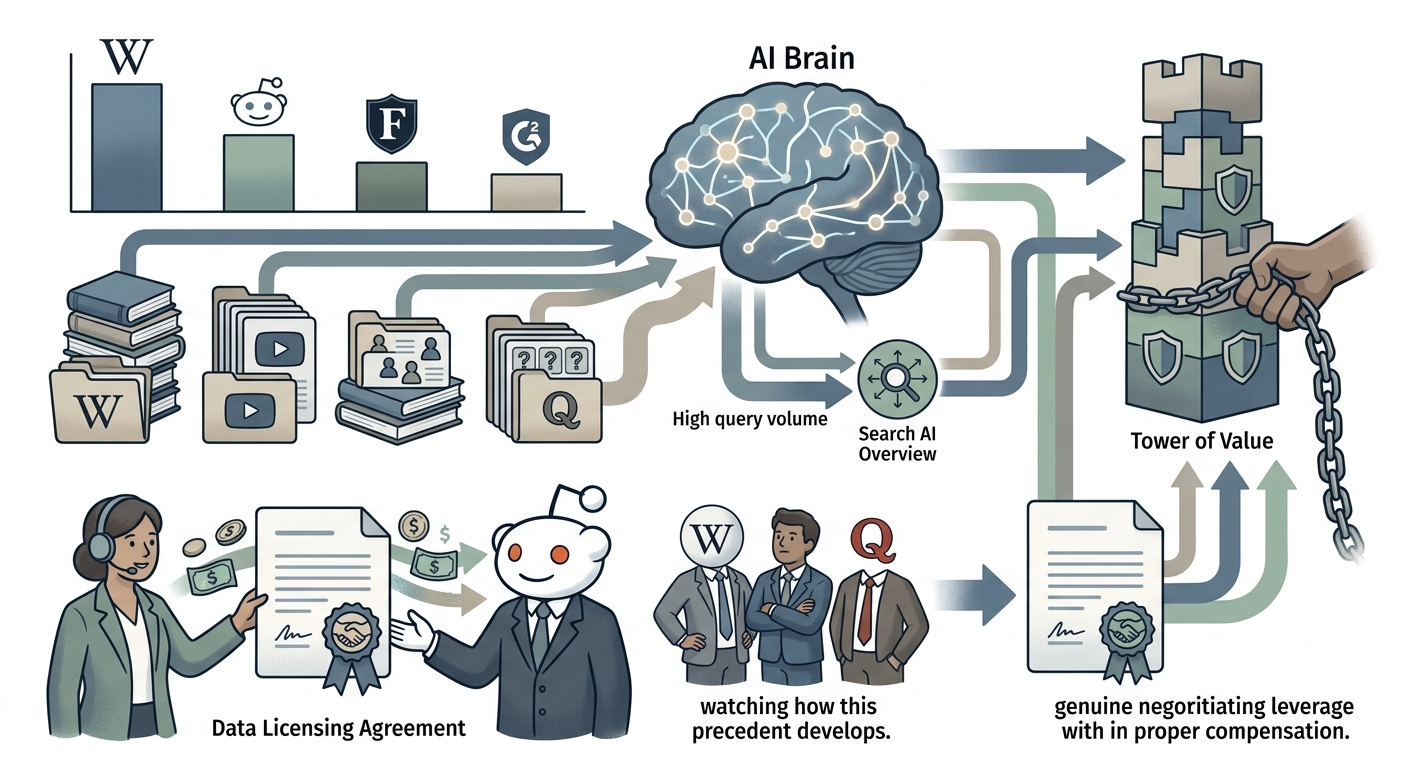
This dispute is a small but clear preview of a much larger conversation that is developing about who owns and who should be compensated for the web data that makes AI systems work.
Wikipedia is the most cited source in ChatGPT at 7.8%, followed by Reddit at 1.8%, Forbes at 1.1%, and G2 at 1.1%. Google is more likely to pull data from Wikipedia, YouTube, Reddit, and Quora for AI Overview responses.
Every platform on that list is seeing enormous AI query volume against its content without a corresponding revenue arrangement. Reddit negotiated a data licensing deal with Google in 2024. Others are watching how that precedent develops.
The pattern emerging is that platforms with unique, user-generated, highly-cited content have genuine negotiating leverage with AI companies that need their data — and they are increasingly willing to use it.
The Proxy and Data Market Connection
For businesses that depend on web data collection for competitive intelligence, pricing research, or market analysis, this shift in the data economy is directly relevant.
As major content platforms establish data licensing norms and some begin restricting AI crawler access to their content, the public web data landscape gets more fragmented. Data that was freely crawlable three years ago may be behind licensing agreements or bot-blocking infrastructure today.
The proxy and data services market exists precisely to navigate this complexity — and the economic pressures driving platforms toward data licensing are the same pressures making premium proxy infrastructure more valuable for legitimate data collection use cases.
💬 Reddit — r/artificial and r/technology discussing Wikipedia AI payment demand: 🔗 https://www.reddit.com/r/technology/search/?q=Wikipedia+AI+companies+pay+2026
🐦 X/Twitter — debate on whether AI companies should pay Wikipedia: 🔗 https://x.com/search?q=Wikipedia+AI+companies+pay+fair+share+2026&f=live
💬 Quora — should AI companies pay Wikipedia and content platforms for data: 🔗 https://www.quora.com/search?q=AI+companies+pay+Wikipedia+data+licensing+2026
Quick Links: